Amazon S3
Setting up the S3 source connector involves creating a read-only S3 user and configuring the S3 connector through the Fabriq UI.
Prerequisites
This page contains the setup guide and reference information for the Amazon S3 source connector.
| Feature | Available |
|---|---|
| Full Refresh Sync | Yes |
| Incremental Sync | yes |
| Replicate Incremental Deletes | No |
| Namespaces | No |
Path Patterns
This connector can sync multiple files by using glob-style patterns, rather than requiring a specific path for every file. This enables:
- Referencing many files with just one pattern, e.g. ** would indicate every file in the bucket.
- Referencing future files that don't exist yet (and therefore don't have a specific path).
You must provide a path pattern. You can also provide many patterns split with | for more complex directory layouts.
Each path pattern is a reference from the root of the bucket, so don't include the bucket name in the pattern(s).
Some example patterns:
- ** : match everything.
- */.csv : match all files with specific extension.
- myFolder/*/.csv : match all csv files anywhere under myFolder.
- */** : match everything at least one folder deep.
- */prefix.csv : match all csv files with specific prefix.
- */prefix.parquet : match all parquet files with specific prefix.
- Let's look at a specific example, matching the following bucket layout:
Connect
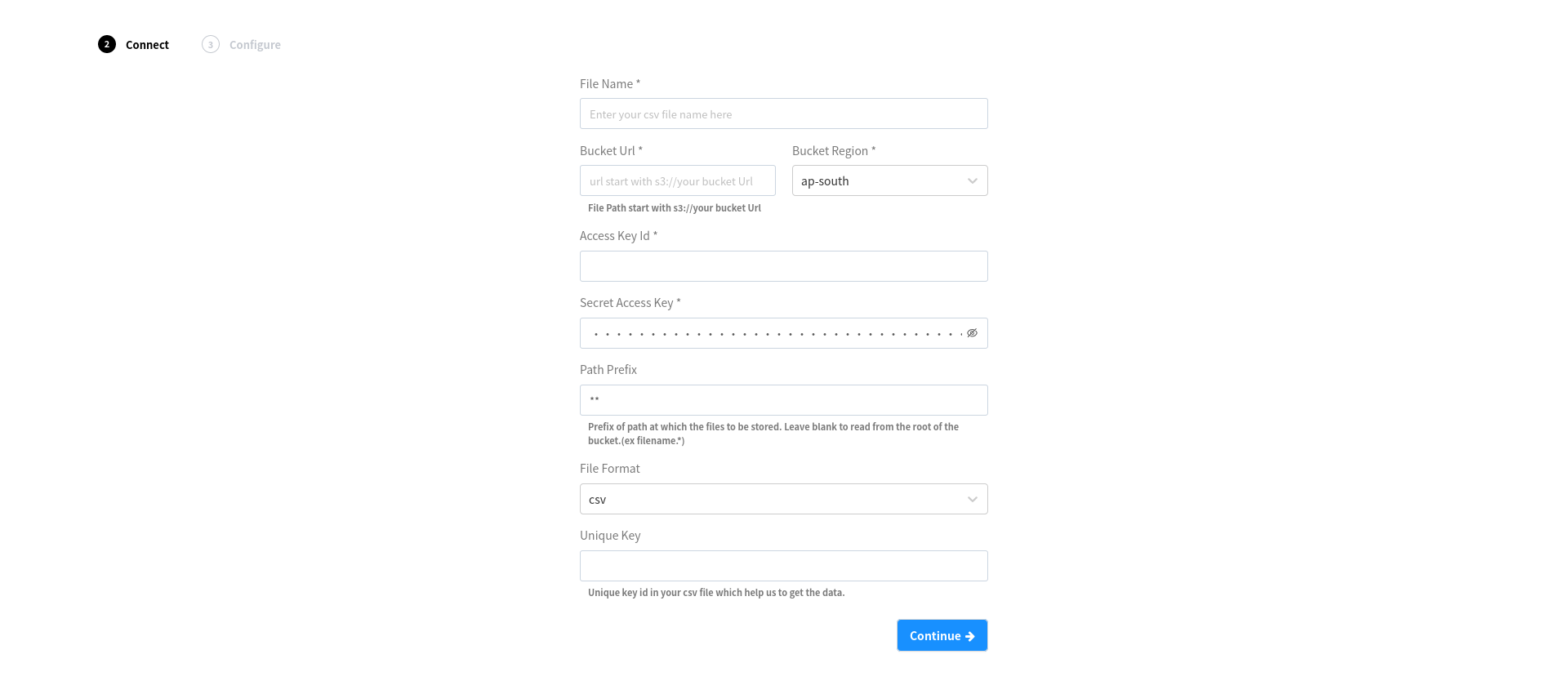
- File Name - Pick a name to help you identify this source in Fabriq.
- Bucket URL - Name of the S3 bucket where the file(s) exist.
- Bucket Region - Region of the S3 bucket account exist.
- Access Key Id - In order to access private Buckets stored on AWS S3, this connector requires credentials with the proper permissions.
- Secret Access Key - In order to access private Buckets stored on AWS S3, this connector requires credentials with the proper permissions.
- Path Prefix - By providing a path-like prefix (e.g. myFolder/thisTable/) under which all the relevant files sit, we can optimize finding these in S3. This is optional but recommended if your bucket contains many folders/files which you don't need to replicate.
- File Format
- Unique Key - Unique key id in your csv file which help us to get the data.
- After entering the details & click continue.